
There was a time at Relay when shipping to production used to be a deliberate and time-consuming process.
We’d deploy 5–7 times a week, carefully coordinating across teams, resolving merge conflicts, and waiting for QA to give the green light. While it worked, there was plenty of room to make it faster, smoother, and less stressful. Today, we’re shipping over 100 times a week, a massive leap from our old pace. We’re not bundling huge features; we’re delivering small, independently shippable pieces that let us test, iterate, and learn without piling on risk. This transformation didn’t happen overnight. It took a deliberate effort to accelerate our learning by changing how we work and levelling up our deployment machinery, making continuous delivery not just possible, but sustainable.
In this article, we’ll explore:
The mindset shift: how we moved from big, risky releases to fast, iterative deployments.
The technical upgrades: from automation to observability, the systems that power our speed.
How this played out with a real release
Let’s dive in and share what we learned along the way.
Where we started: Just over 6 deployments per week before we transformed our process.
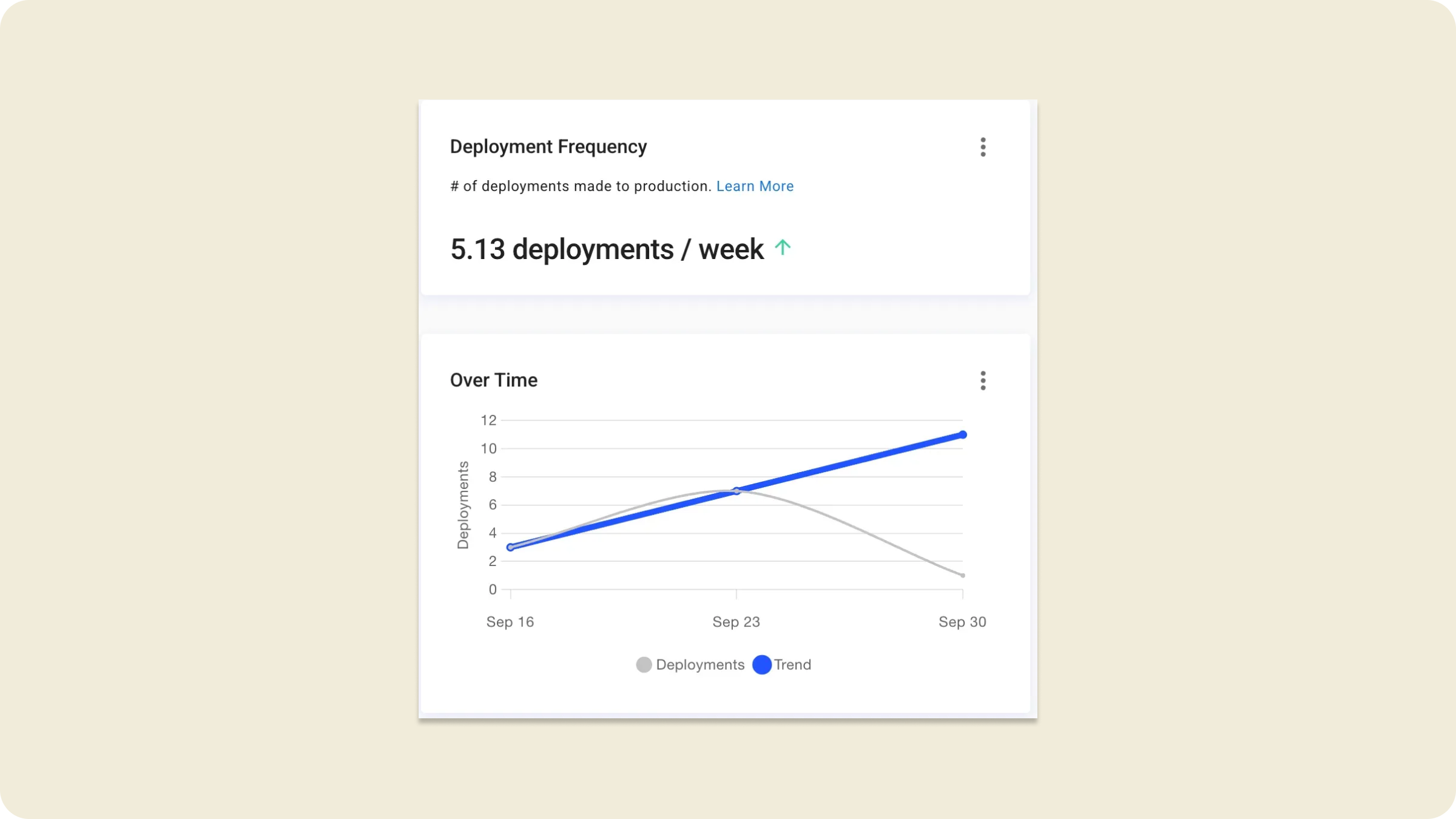
(September 2024 – 5 deployments per week)
Our current deployment frequency: Shipping at scale with over 95 deploys per week.
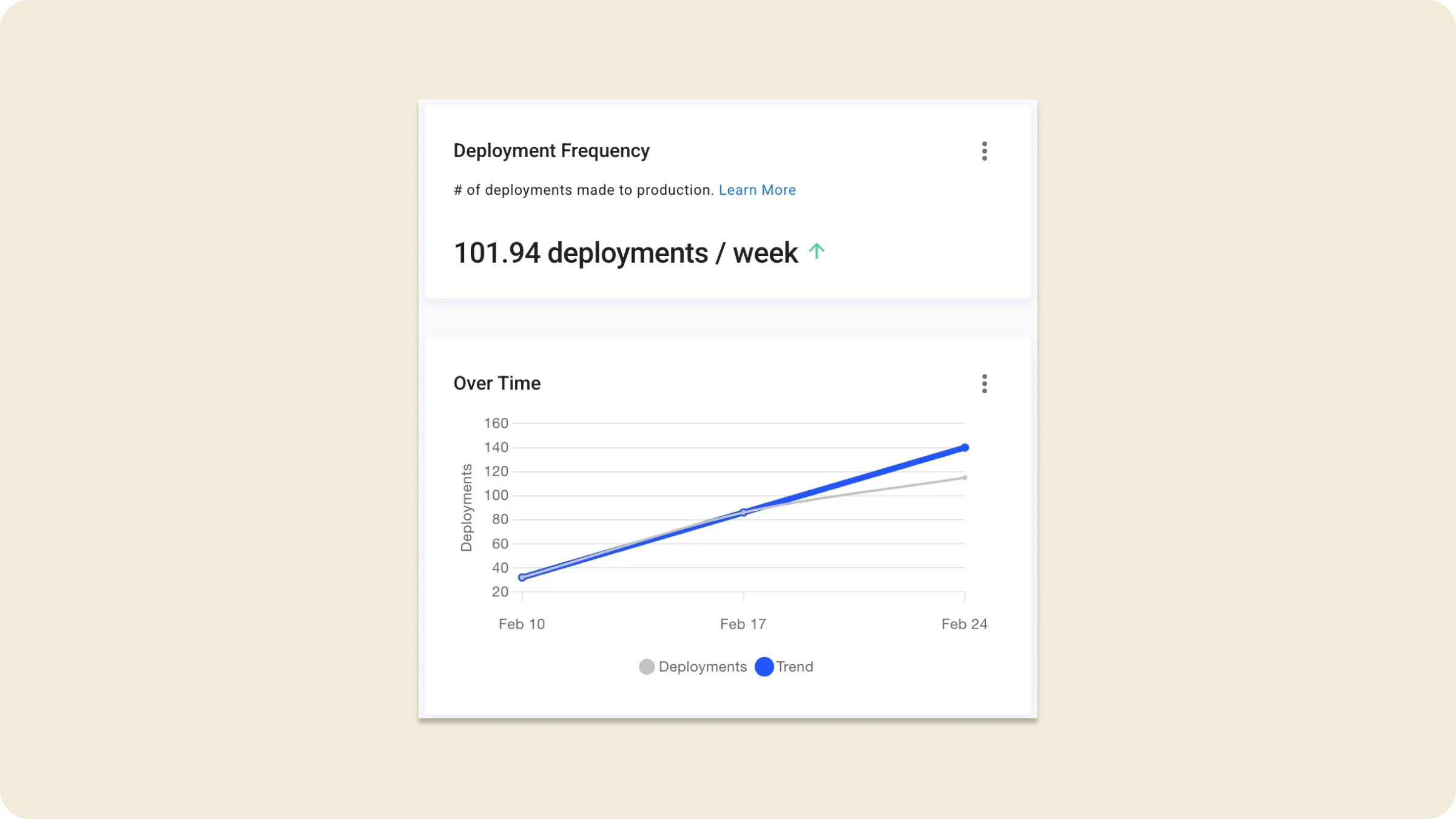
After (February 2025–101 deployments per week)
The Mindset Shift - Changing How We Work: Smaller, Smarter, Faster
From “Big Bang” Releases to Vertical Slices
Previously, we’d batch features into massive, all-or-nothing releases. One bug could hold everything hostage, delaying launches and impacting multiple teams. Merge conflicts ran rampant, QA cycles dragged on, and by the time we shipped, we were already behind on our next milestone.
Now, we work in small, independently deployable slices, each gated by a feature flag. This lets us merge to production early and often, reducing risk while increasing flexibility. This shift has led to shorter release cycles, fewer merge conflicts, and Faster, real-world feedback so we can validate through usage rather than assumptions.
This required a shift in how we collaborate. Engineers and PMs now focus on defining the smallest valuable slice, iterating rapidly instead of over-planning. Deployments are no longer treated as major events but as part of our daily engineering rhythm. Each engineer integrates code at least once every 24 hours, keeping everything in sync.
This isn’t just a process change; it’s a cultural shift. We think in deployable units, embrace iterative improvements, and trust that shipping frequently is actually safer than shipping rarely.
It could feel daunting for members of the team who were previously going through a longer cycle to one where they are shipping multiple times a day. As we continue to expand our test automation, the automated safety net for every deploy gets stronger and stronger. As each change hitting production is smaller in scope, the levels of risk ultimately fall. A small, well focused PR is much easier to review and get confidence that the change is safe to immediately deploy.
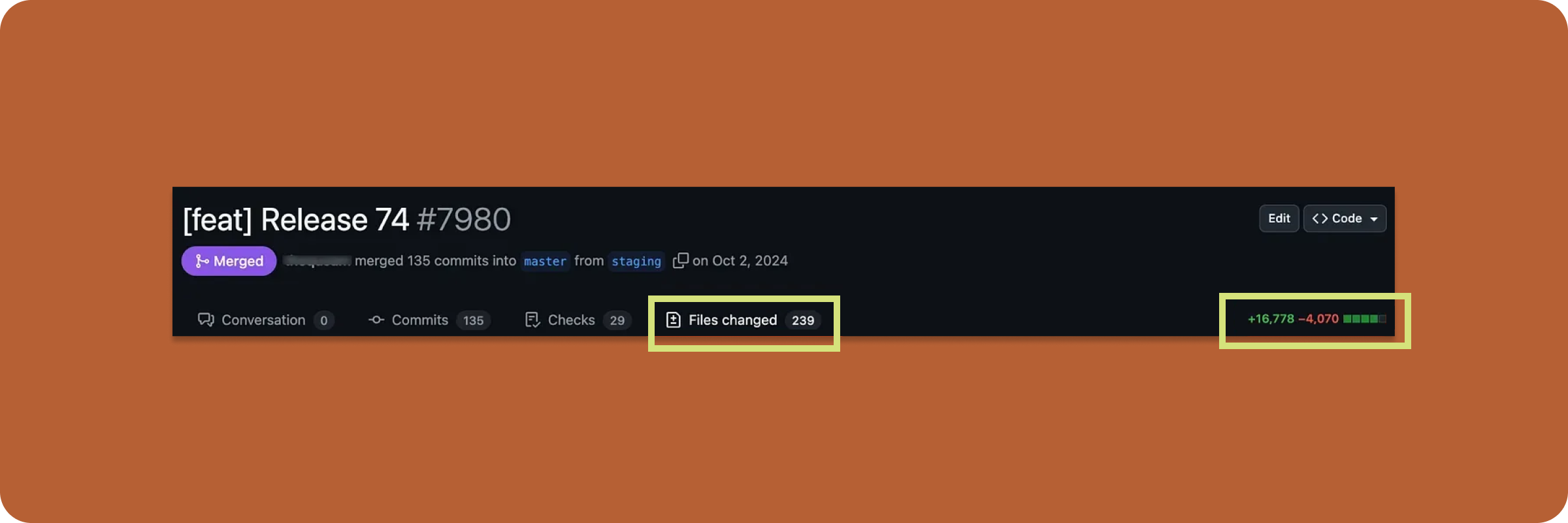
Before: large batch releases with hundreds of changes.
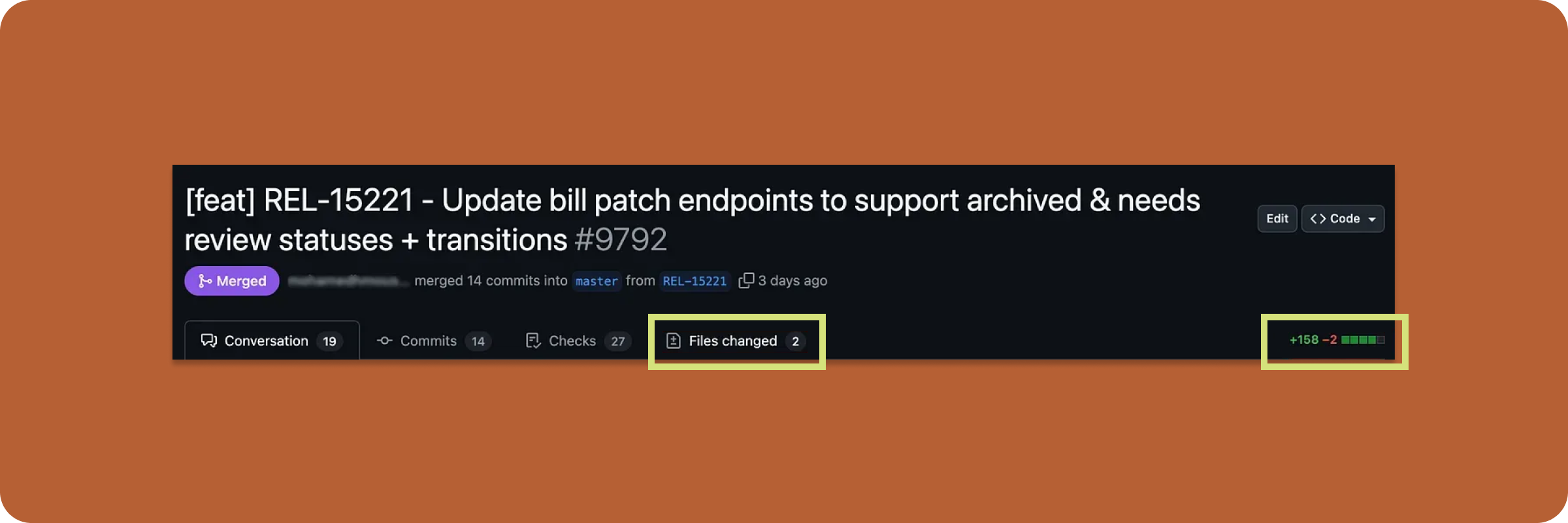
After: small, focused, and quickly merged.
The Technical Upgrades - Enhancing Our Delivery Machinery
1. Trunk-Based Development, the PR template, and the Merge Queue
We moved away from long-lived feature branches to a trunk-based model, merging small changes into the trunk branch early and often. Each PR follows a standardize template acting like a checklist that ensures we cover all the essentials: the type of change, what changed, why it matters, how it was tested. Then spins up an ephemeral preview environment, a sandbox for quick QA and smoke tests. Once validated, the PR heads to our Merge Queue, which acts like a traffic controller where only changes that pass automated checks get merged, ensuring our trunk stays stable and release-ready.
2. Fully Automated Deployments
Once a PR is merged, our pipeline does the heavy lifting:
Builds a fresh container image.
Runs all tests in parallel to confirm nothing’s broken.
Rolls Out the updated pods to our Kubernetes cluster if everything looks good.
3. Feature Flags
When we need to ship a feature before it’s entirely ready, or gradually release it to a fraction of your user base. That’s where feature flags shine. We deploy code in a dormant state and flip the switch only when we’re confident. If there’s a hiccup, we flip it right back off without the need to block or roll back the entire release.
4. Post-Deployment Monitoring & Observability
Shipping faster means spotting issues faster. Our observability stack includes real-time dashboards for performance metrics, error rates, and more. We also use automated alerts to instantly notify the right teams in Slack, often before customers notice any hiccup. This setup ensures we maintain our speed without sacrificing reliability.
5. Streamlined Database Migration Process
Databases can be a sticking point in continuous delivery, so we overhauled our migration process. By automating each step and ensuring backward compatibility, we can release schema updates independently of application changes.
Changes in Action
The team applied these new ways of working while building out a more comprehensive spend management product for our users. A key factor in the smooth GA release was the team’s shift towards shipping smaller, more frequent changes, which was enabled by a stronger trunk-based development approach. Because we weren’t blocked by staging freezes, we could continuously merge and deploy updates, reducing bottlenecks and enable to iterate quickly. Standardizing ticket descriptions improved clarity, and stronger alignment between engineering and product meant we had a clear understanding of what we were shipping and when. This kept momentum and morale high. Rather than working towards a single, large release, we made steady progress with multiple, well-defined milestones.
Another important aspect was keeping the scope in check. With a stable goalpost, the team could stay focused and systematically review remaining work every day. A bug bash in the end also played a big role in raising confidence and reducing risk ahead of GA, and having embedded QA helped accelerate testing while maintaining quality. Altogether, these practices made our release process more predictable and efficient. All on the shoulders of our drive to accelerate learning.
Key Takeaways
This wasn’t about going fast just for the sake of it. We focused on real impact, measuring DORA metrics to track improvements and continuously refine our approach.
More than anything, this was about learning faster. By deploying in small, safe increments and automating everything we could, we gave ourselves the freedom to experiment, gather feedback, and improve.
We didn’t flip a switch overnight. Just like we aimed to ship faster and learn from users, we took the same approach internally. Starting small, gathering feedback, and refining as we went.
Along the way, we had some challenges, as well as some existing support pushing us forward:
Our CI/CD pipeline wasn’t built for this pace. Fix: We optimized builds, parallelized tests, and introduced a merge queue.
Some team members were worried that daily deploys would be risky.
Fix: We shared data, ran training sessions, and gradually rolled it out.
More deployments meant faster failures. Fix: We improved observability with real-time alerts and log aggregation.
We had an existing set of automated tests which we could rely upon as a safety net, but we also ensured each team had a dedicated QA team member, as we also increased our automated safety net.
Each step made the next one easier. Now, shipping daily feels normal and safer than waiting weeks. We’re always improving, and looking to implement deeper automation and smarter observability to make deployments even smoother.
As we continue to refine and iterate, we expect within a few months that we’ll be shipping well over 200 times per week, with safety.
If this sounds like the kind of engineering culture you want to be part of, come join us.
